Continuous Deployment-as-a-Service
Summary
Time Period: Fall 2021 - Summer 2022
Objective: Build a new product aimed at engineering teams with the purpose of making their software deployments safer and more reliable, using Kubernetes as the primary vehicle for doing so.
Outcomes: Between the fall of 2021 and spring/summer of 2022, we went from 0-1 to build the platform from scratch. After launch we made additional UX improvements which increased our onboarding funnel success from roughly 2% to 40%.
Additional Notes:
Due to market forces and Armory’s core product being unable to sustain the business, the company had its assets sold to Harness and ceased operations in January 2024. This product is no longer available as a result.
The writeup below is not exhaustive and merely serves to highlight some of the key challenges we faced.
Background
About Armory
Armory was a YCombinator startup founded in 2017 whose business was in the DevOps space. Their most recent round of funding was their series C in October 2020, shortly before I joined the company in 2021. At the time, the vast majority of their revenue was based around a platform called Spinnaker.
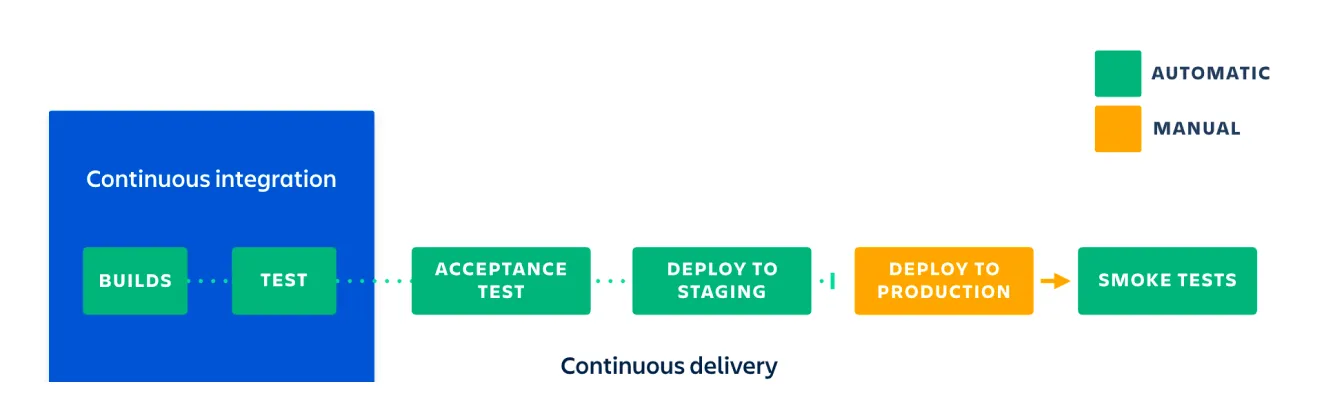
What is Spinnaker?
Spinnaker is an open-source continuous delivery platform. It was originally built by Netflix and released to the public in 2015. it supports deployment via multiple platforms including Kubernetes, AWS, Azure, GCP, and Oracle.
Spinnaker operates under open-source governance, with a committee of individuals spanning numerous companies (e.g. Google, Red Hat, and IBM) who manage its roadmap and development.
Armory’s business model
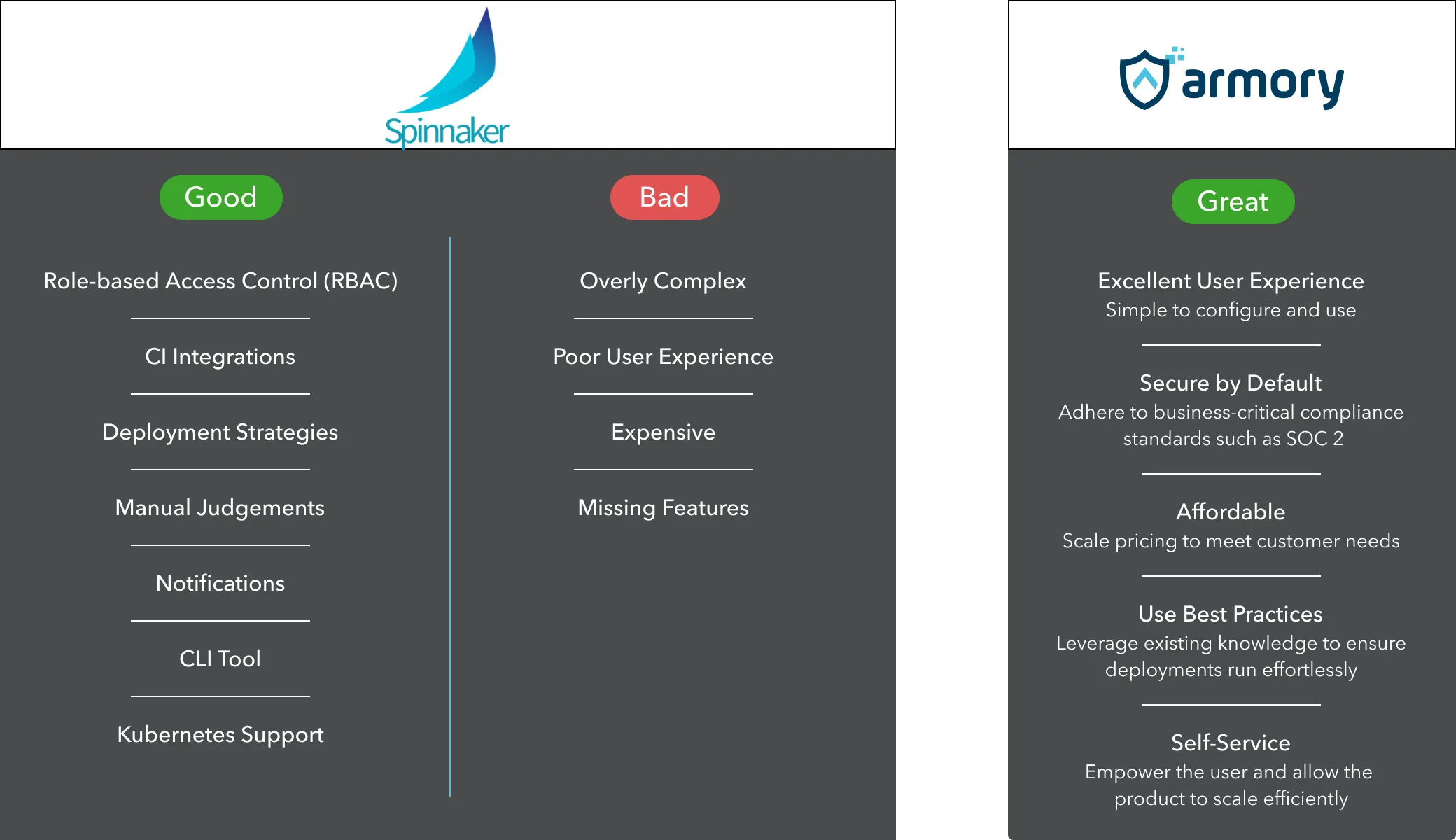
While Spinnaker is an extremely robust platform, it lacks many features out of the box such as secrets management or pipelines-as-code. Armory developed and sold proprietary plugins that filled these gaps. Additionally, Armory’s other revenue driver was via managed services, a white glove service where they helped set up and maintain the customer’s Spinnaker instance, ensuring it functions effectively and delivers the value it should.

Armory was one of only players in this space (a similar competitor is OpsMx), so from a business perspective, this could be considered a great place to carve out a niche as a startup.
Challenges
Despite the above, Armory faced numerous challenges to their business model.
As Spinnaker was built by Netflix to solve its scale of problems, the platform was overkill for the vast majority of customers and thus a difficult sell. Onboarding was on a scale of months, the Spinnaker UI was bloated (and remains so to this day), and customers may have wanted a more complete solution out-of-the-box. As a result, the total addressable market for Spinnaker was very small. Managed services also didn’t align with a mid-stage startup’s primary goals of scaling and driving revenue.
Additionally, due to the nature of open-source governance, there was not one specific company behind its development, potentially leading to an uncertain future. For contrast, in my time at Microsoft, we worked .NET SDKs that the company held a direct business interest in; although the SDKs themselves were not a revenue driver, developers using them could lead to Azure attachment.
Continuing to tie Armory’s future to Spinnaker posed a great risk to the company’s viability over the long term, and we decided to build a new product to expand horizontally and grow both our customer base and revenue.
Building Continuous Deployment-as-a-Service
How previous experiences shaped my process
I was a product manager working on mobile development tools over several years at Microsoft. Most of this time was spent working on .NET SDKs, but also included UX work on the Visual Studio, which developers used to build apps. You can read about some of that work over here.
Over the years I observed that our tools were not popular with new–and especially younger–developers. My belief was that as developers gain experience over many years, they eventually learn that all tools have their own quirks and flaws. However, as long as they generally get the job done, they’re fine enough.
From that came a guiding principle: always design with the least experienced developer in mind. A frictionless UX for a new user means an even smoother experience for the expert, especially relative to other tools they’re accustomed to.
The experience applied to CD-as-a-Service
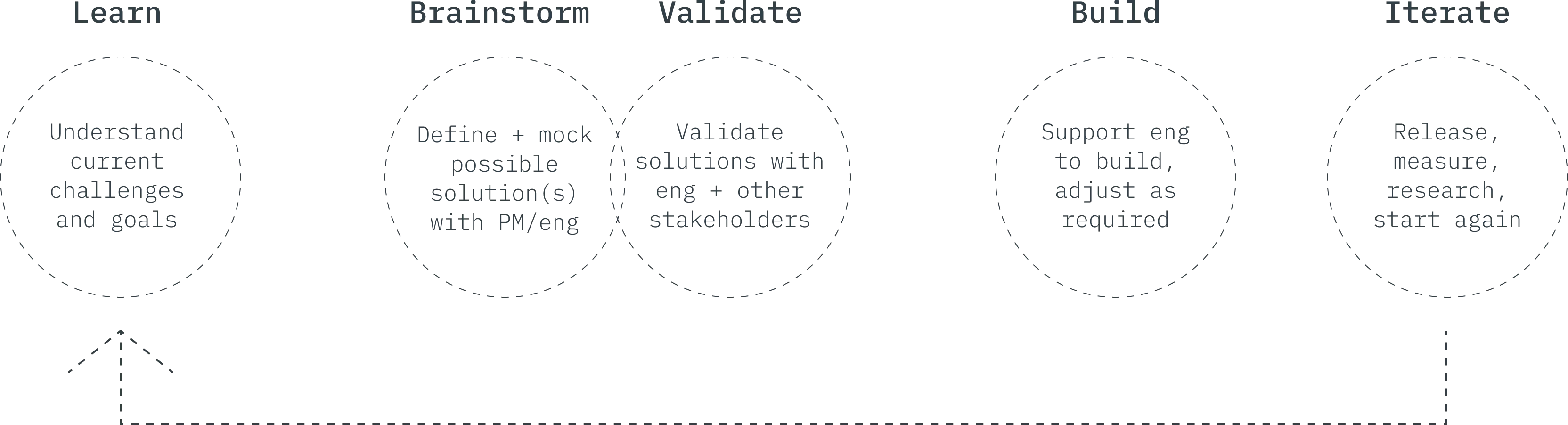
While my ideal process is similar to something below, every company and team is different, and you’ll often have to adjust and make the best use of the resources which are available to you. In our case, we didn’t have external resources–at least not early on–and due to the various constraints and the type of product we were building, brainstorming and validation were much more tightly coupled, involving the engineering team just about every step of the way. One of the most valuable traits I’ve grown over the years is the ability to be flexible, especially within the scope of product design, as constraints will always vary based on available information, resources, and technical ability.
Team structure and challenges
Our primary constraints revolved around available resources and the problem space. Additionally, despite having a background in developer tools, DevOps was new to me, and understanding the key challenges users faced was essential in building a new product.
Regarding our team structure, we had two pods of engineers for both frontend and backend work, as well as some floating contributors. The product manager and I were essentially members of both pods.
What do we build?
Spinnaker did a lot of things we liked, but we wanted to build something easier to use that could also reach a broader market. We could use our existing knowledge to adhere to common usage patterns, while building horizontally to tap into a much broader potential market. From a design perspective, I didn’t think that there was a problem with what Spinnaker was trying to do, but that it was trying to do too much and was simply too complex. I recall having a very interesting conversation with our CEO at the time, talking about how I envisioned continuous deployment.
We knew that Spinnaker was trying to be too many things to too many people. We also knew that Kubernetes was the industry standard for deployment orchestration. Rather than focus on supporting multiple platforms, thus increasing time to development and overall complexity, we’d carve out a niche of doing one thing right with one platform.
From all these discussions and my own input, we had a goal: build a simpler, more user-friendly Spinnaker which uses Kubernetes as its vehicle for continuous deployment.
While there were competing platforms such as ArgoCD, we would also include some key differentiators; most notably, by being a cloud-based platform, which removed the need for engineers and DevOps teams to manage the installation and management of such platforms themselves. Instead, they could focus on writing and deploying code.
Discovery, brainstorming, and iteration
While I led the design of the user experience and product layout, it was critical to have my teammates involved in every step of the feedback loop. As we were a small startup building a new product from the ground up, this was especially true.
It’s important for anyone in product to be cognizant of the resources available to you. At a company like Microsoft, I had access to thousands of developers in the .NET community with whom I ran frequent 1:1 interviews and quarterly surveys, as well as near-endless amounts of telemetry data to analyze in PowerBI gather insights into usage patterns.
At Armory, the opposite was true; we could certainly gather data and conduct research, but were greatly limited in the scale at which we could do so. Conducting external research was especially difficult until we obtained our first design partners, which were companies that signed on to use early versions of the product and provide weekly feedback. They could also act as champions for the product when it was officially launched.
Due to these limitations, it was paramount that my peers were involved in brainstorming sessions and build out solutions to the problems we faced, even more so than usual. Engineering was critical to help define the small details, and this inclusiveness also matured our culture around UX design and its significance.
User journey & onboarding workflow
In collaboration with our engineering team during the initial discovery and planning phases, we defined our new user journey as following these steps:
- Sign up for an account.
- Install the Armory agent on their Kubernetes cluster, allowing communication with CD-as-a-Service.
- Clone a pre-built sample application from GitHub and deploy it to the cluster using Armory’s command line tool.
- View the deployment in action and engage with the UI to better understand how the product works.
- Proceed to read further documentation and deploy their own application.
Afterward, they would be able to invite other users on their team to try out the platform, and eventually sign up for a paid plan.
A job to be done: the 10,000-foot view
As engineering teams and engineers themselves vary so greatly, our target user was broad and not easy to define. Nevertheless, we could still focus on building a solution to address what we believed to be the core problem. In collaboration with various stakeholders such as our engineers , I defined what I considered to be the key job-to-be-done:
Enable a top-down view of all deployments, diving deep into specific deployment environments within each.
Starting from the top
Comparing the usual deployment pipelines of Spinnaker, we have a simplified version which was an early artifact of our design process (simply due to needing under-the-hood work). It served the key function of allowing the user to view all of their deployments, either finished or in progress, and dive deeper into specific details as needed.
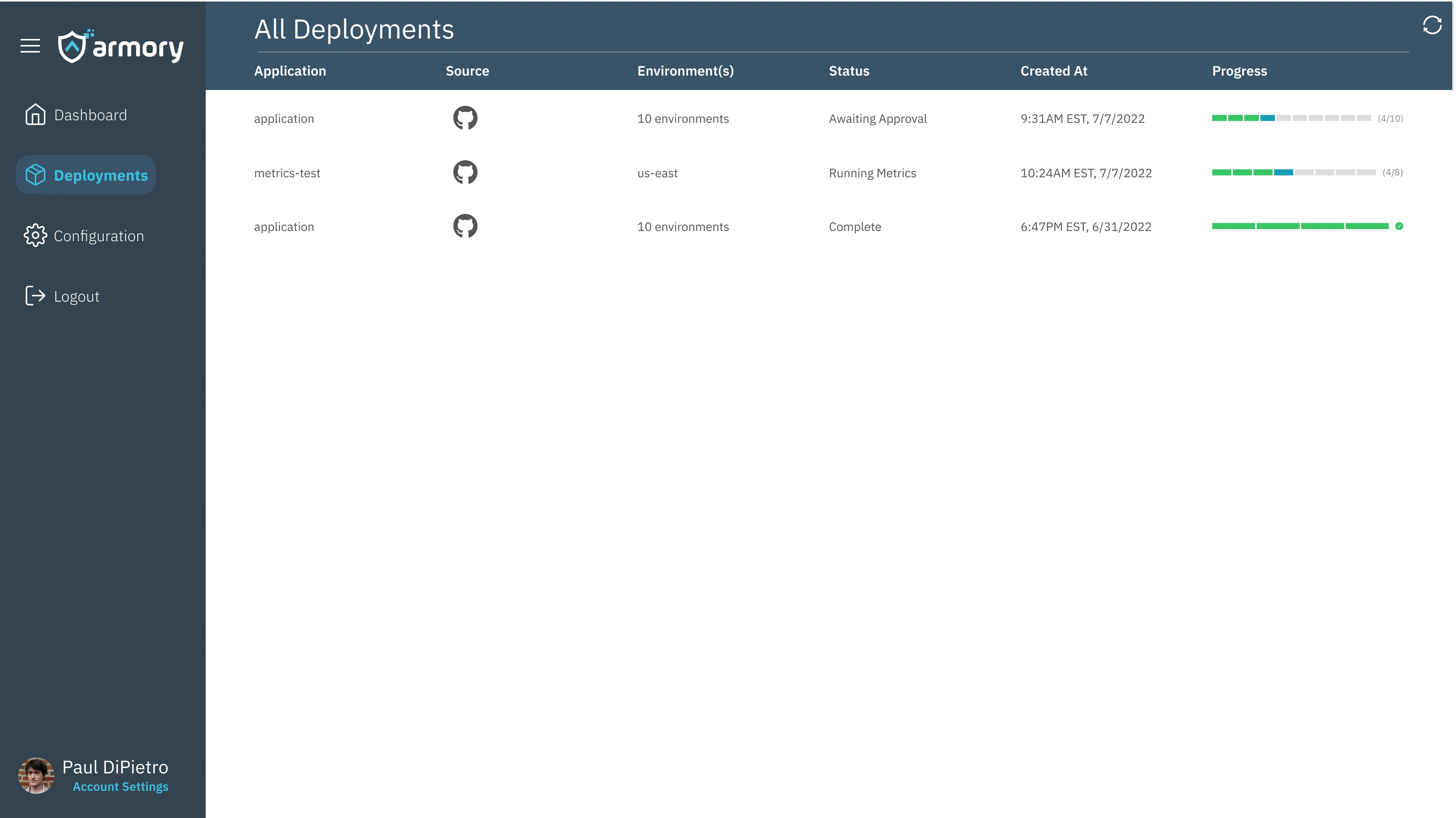
We later learned throughout the development process that our users didn’t necessarily value this page as much, as they’d often just dive into specific deployments which were linked via notifications into things such as Slack. That said, it provided a valuable jumping point and is something I would have made improvements to in the future.
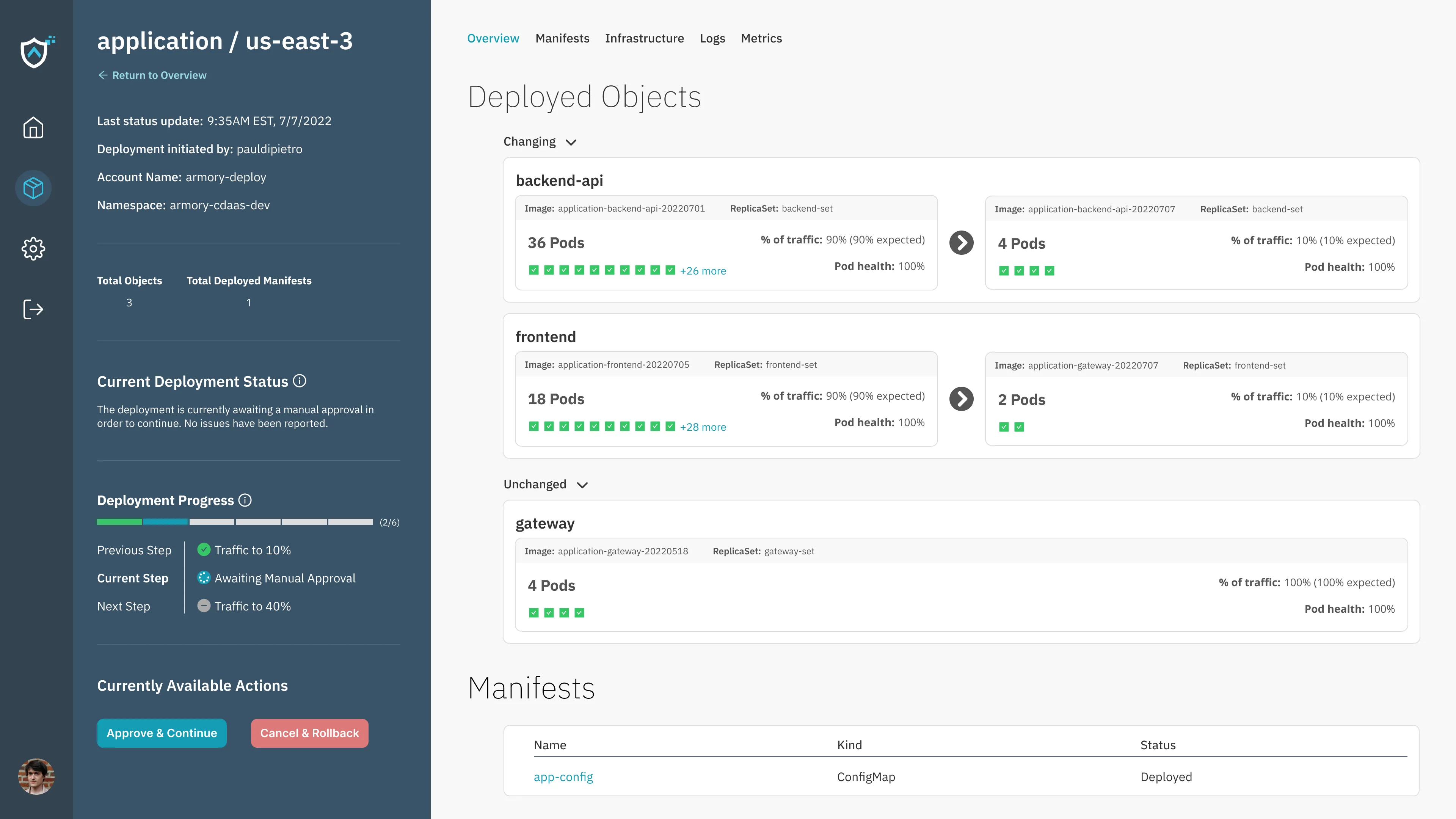
From 1000ft: observing a deployment pipeline
A critical part of our workflow were manifests; files written in YAML which acted as a recipe for how deployments were conducted. They could then dive into details for each as those deployments were executing, most notably if they needed to issue approvals to continue or address something going wrong.
An example manifest might look like this:
strategies:
rolling:
canary:
steps:
- setWeight:
weight: 100
trafficSplit:
canary:
steps:
- setWeight:
weight: 25
- exposeServices:
services:
- my-application
ttl:
duration: 30
unit: minutes
- pause:
untilApproved: true
- setWeight:
weight: 100Each deployment then runs as a pipeline. Each “card” represented a Kubernetes cluster (connected via an agent which lets it communicate with CD-as-a-Service). The lines referred to each “phase” of sorts in the deployment, and in most cases, some environments would depend on the completion of others’ deployments before beginning their own.
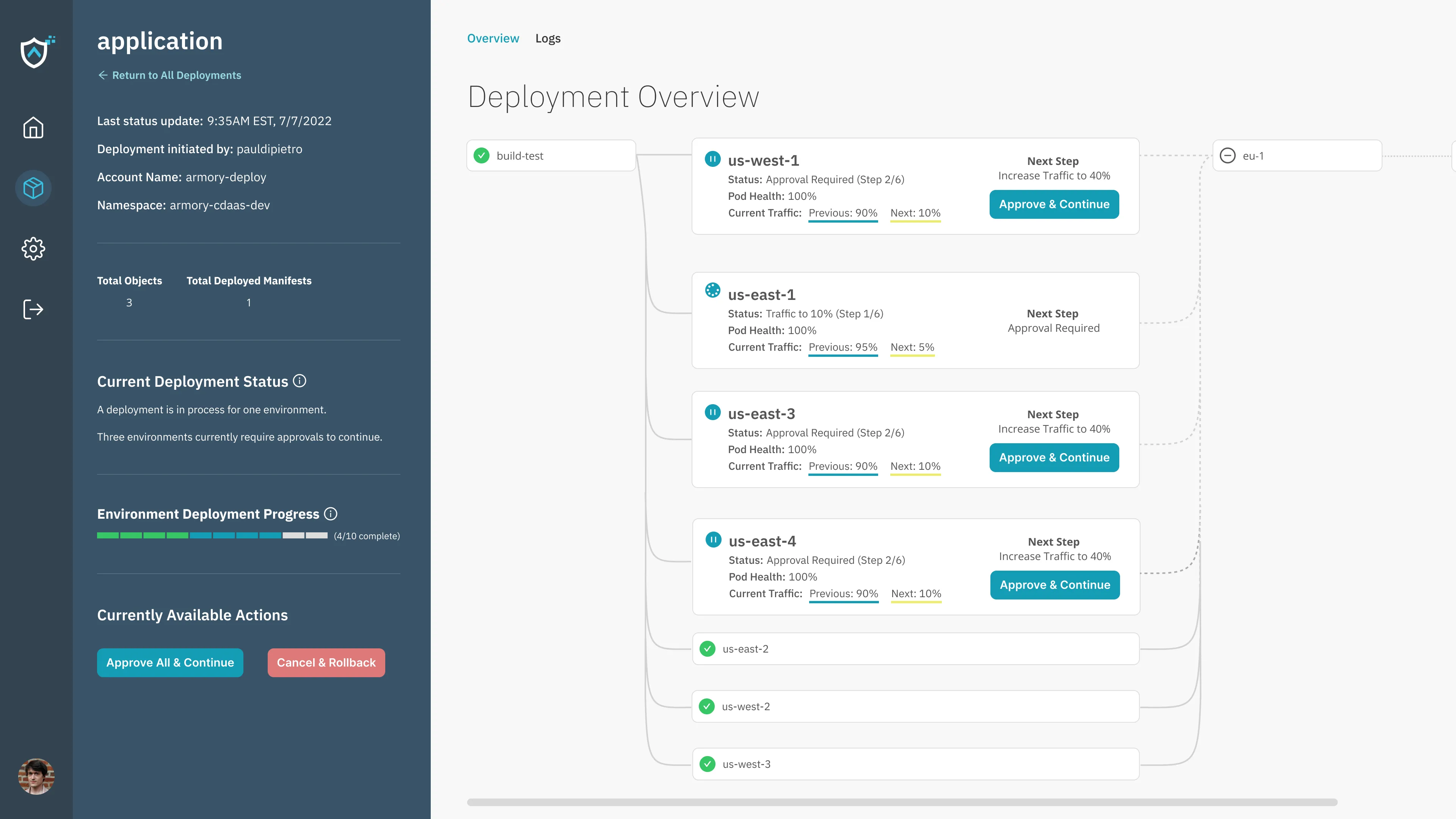
The 100ft view: environments in action
Each environment conducts its deployment using a strategy; supported strategies are different means to the same end. Multiple objects (i.e. applications) can be deployed to each environment. Developers would interact with this when they needed to learn more about a given environment’s state.
While user would generally only go to this view when they needed to better understand what was wrong with an environment, I wanted them to be able to act quickly and easily when they did. Additional elements of interaction not present here include tooltips with basic info when hovering over specific pods.
Additional features
Below are some additional features and views.
A user can look at infrastructure for a given environment, including Pods, ReplicaSets, and Services:
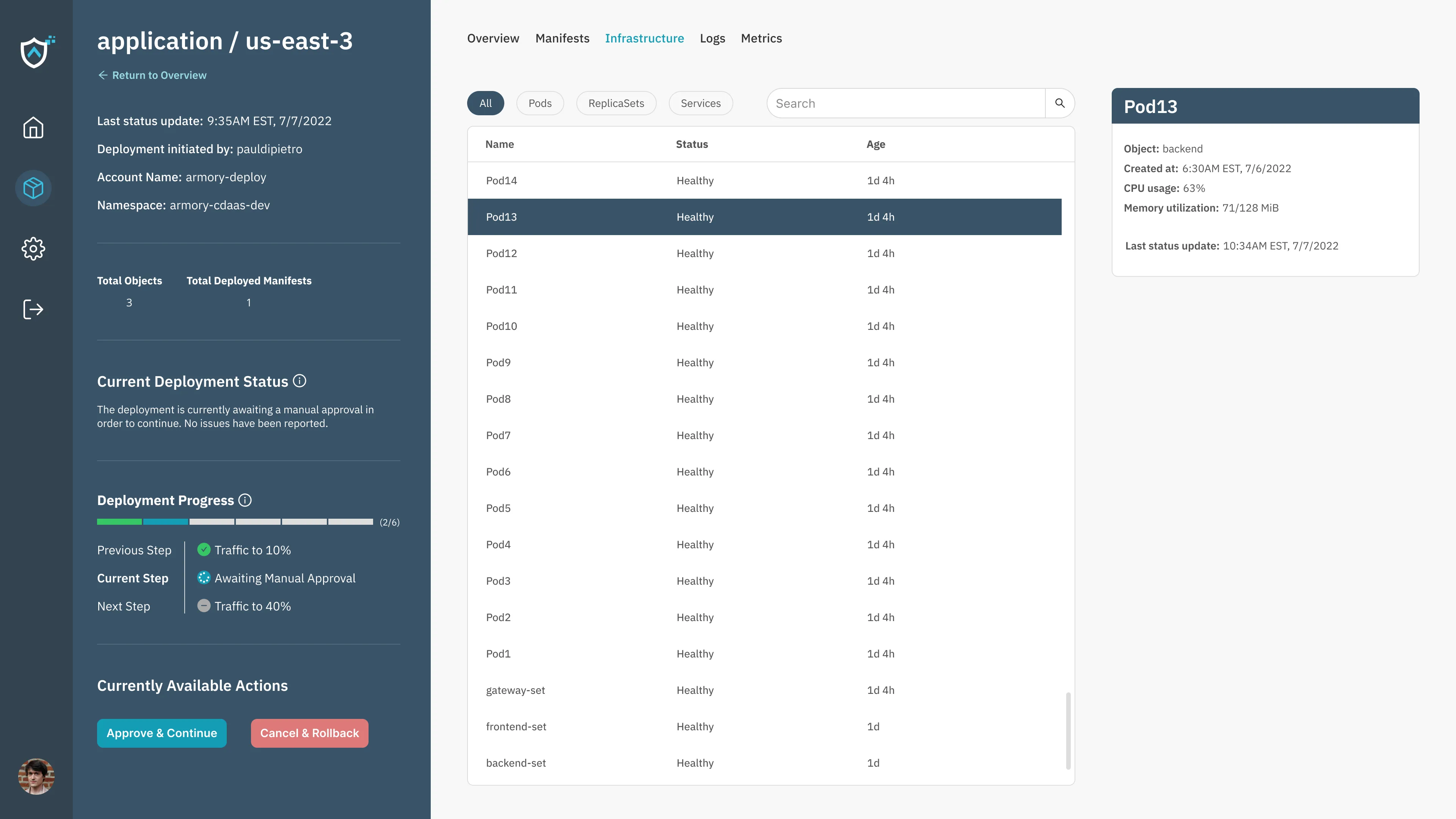
When specific metrics are run, the user can view information related to the given environment:
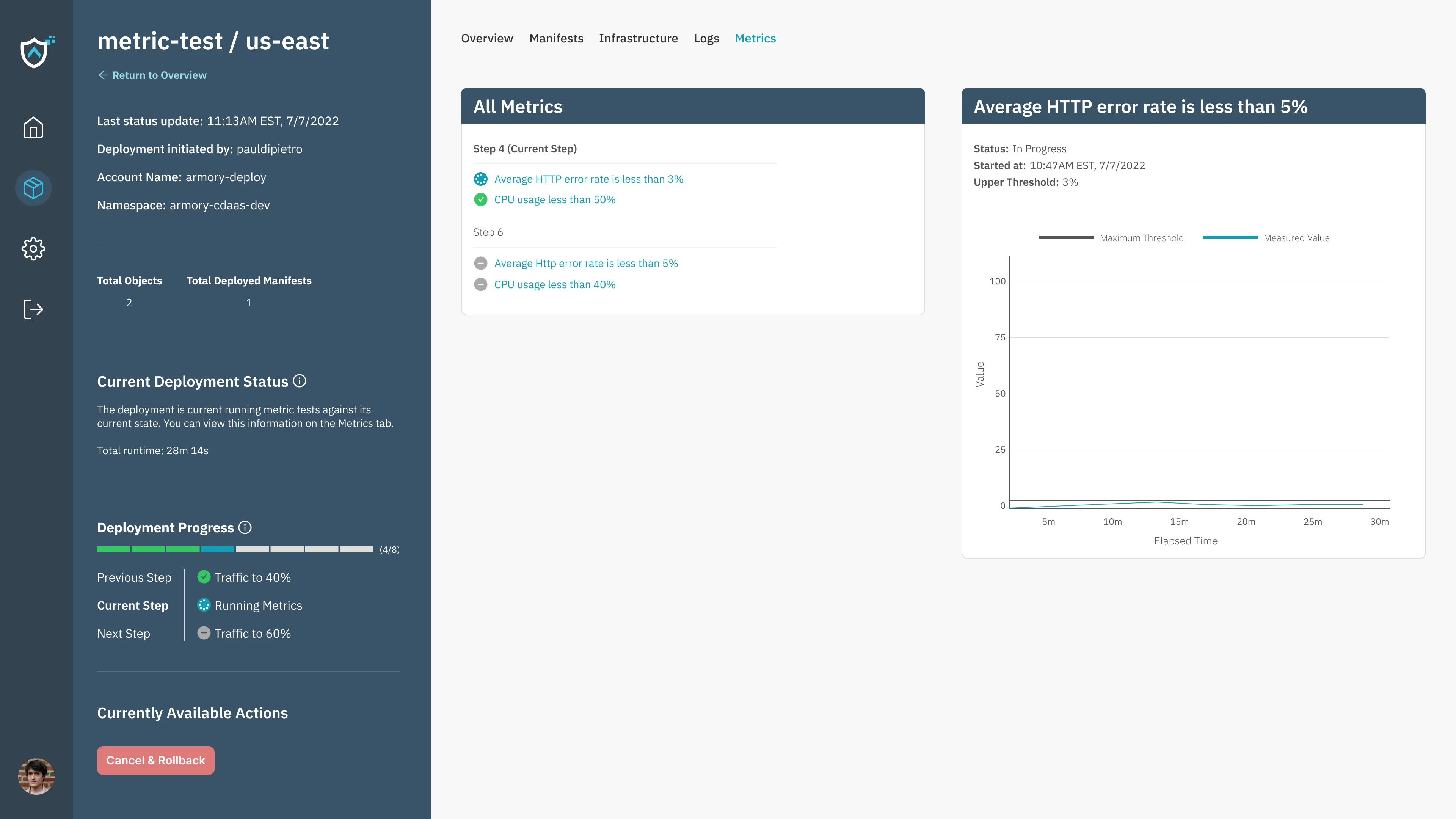
Post-launch onboarding challenges
Our initial success metrics focused on users getting through registration, signing up, and deploying any sort of application. After launch, we kept an eye on usage data via Pendo in order to look for signals of friction. In any product, first impressions are crucial, but this is especially true for a brand new one with only a few users.
Over the course of the product’s initial implementation, a major point of the workflow required users to provide their own Kubernetes cluster to deploy to. A hypothesis prior to launch was that our users would be less than inclined to do this due to a variety of reasons, such as the following:
- Uncertainty about the security of the agent
- An inability to access company infrastructure resources (e.g. AWS, Azure, etc.) to set up a cluster
- An inability to make changes to an existing cluster (e.g. production)
- Some level of understanding of their company’s CI/CD process, but a lack of knowledge about Kubernetes and setting up clusters
Any of the above could and did eventually cause user drop off, as we eventually found out.
During the design phase, I proposed the concept of a “demo” cluster which CD-as-a-Service would provide for the sole purpose of demoing the sample application. This would potentially reduce user friction around the above issues. We eventually decided to omit this feature and track our onboarding funnel data.
Why did we do this? In short, implementing anything “automatic” could require a substantial engineering effort with a variety of risks. In the case of automatic cluster generation primarily around cost and security of running our own Kubernetes clusters for external users, for free. It was not mandatory for the product to function, and we simply didn’t have the user base or resources for research to determine the impact it would have. An additional argument against the feature was that our most likely user would be knowledgeable (and willing) enough to complete the requirements to try the product.
My background in development let me better empathize with these potential technical challenges, and as a group we consciously made the decision as a team.
Eventually, we found that users were not getting past the first step of setting up their cluster. We ran some hands-on sessions with the product for further research. During those sessions, none of our users ever got past that point without our aid. With that eventual research data in hand, I was able to map the decision-making process that users went through. Below was just for the process of setting up a cluster for deployment:
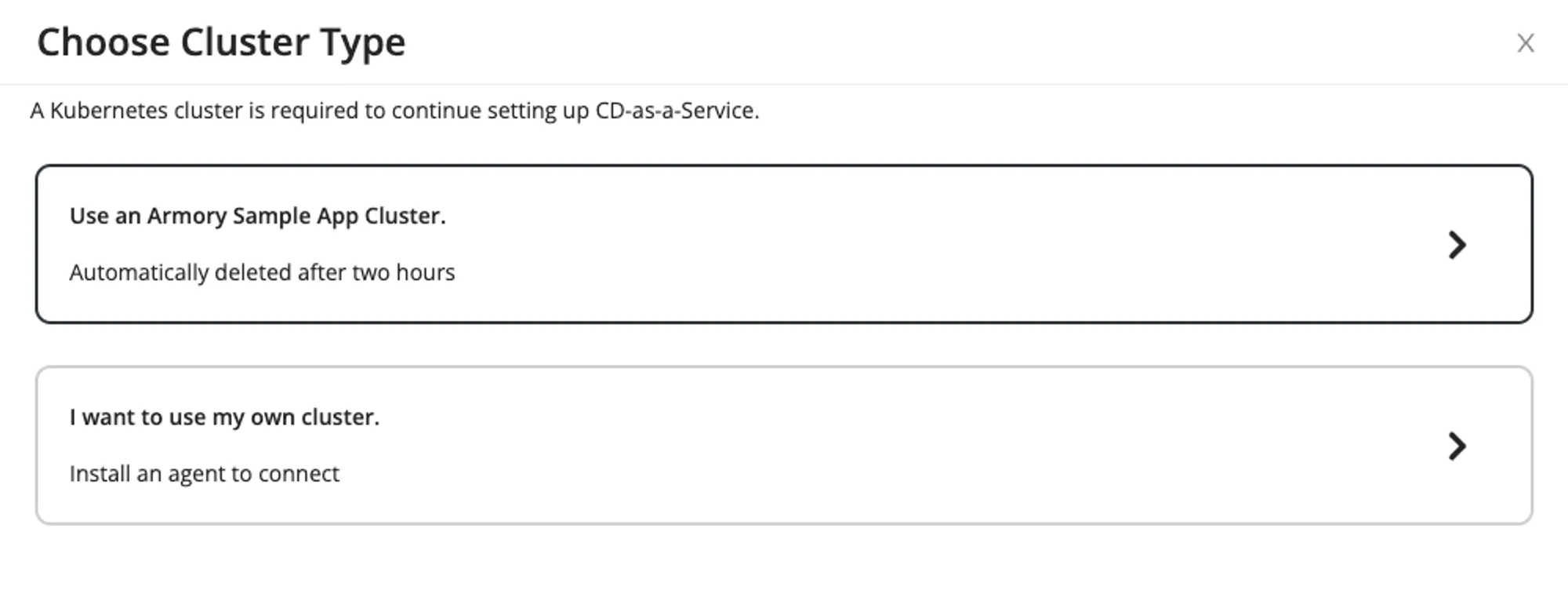
Having this information, and in collaboration with our engineering team, we eventually devised a reasonable way to provide a Kubernetes cluster for our users, as well as a one-click deployment of the sample app. We called these sandbox clusters.
Our initial implementation was quick and dirty, but the focus was on rapidly improving ease-of-use, rather than looking perfect.
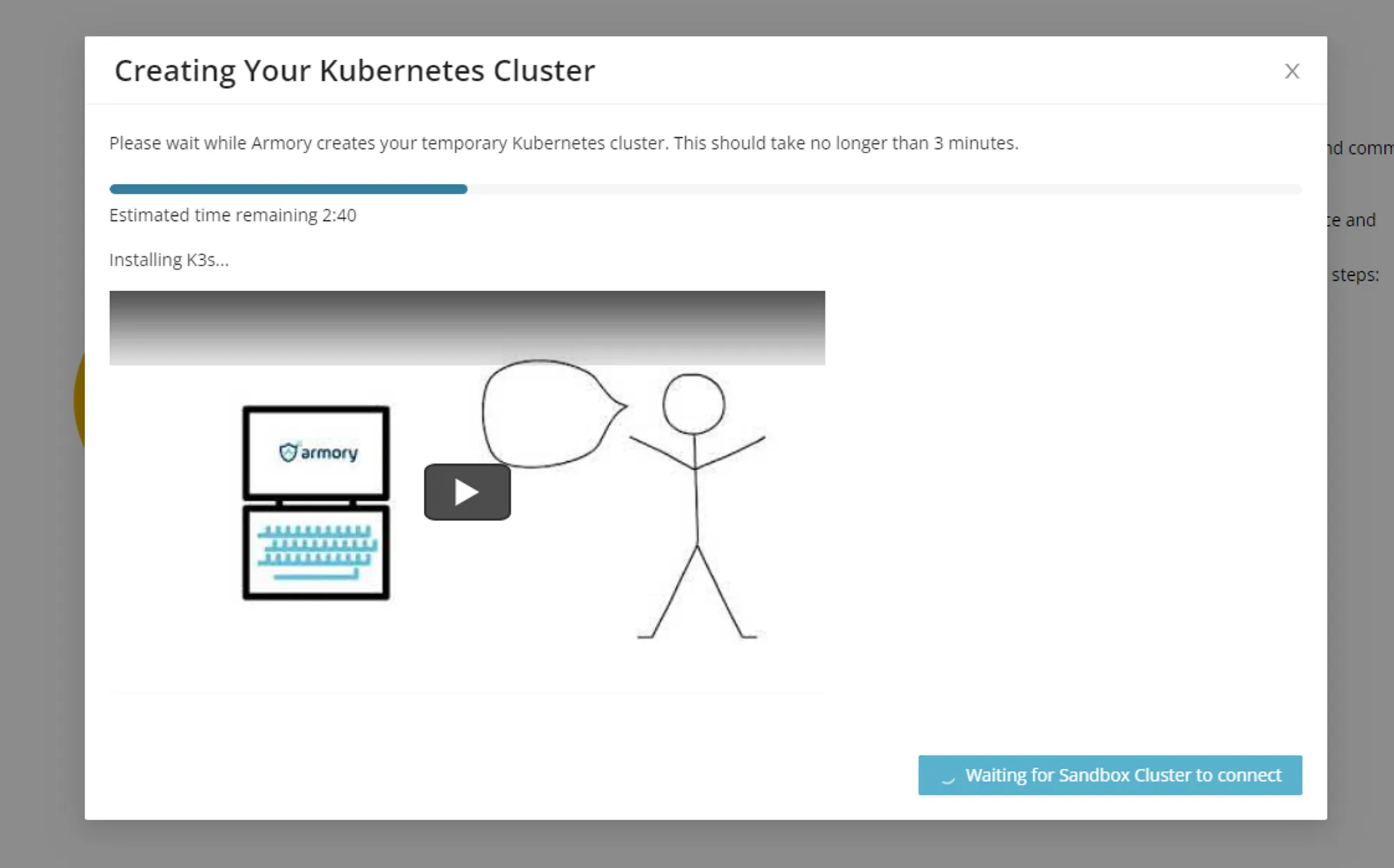
Sandbox clusters are automatically created for users should they opt for them, and only had a lifespan of two hours. Following the creation of the cluster–which included a progress timer and helpful video to help pass the 2-3 minute wait–a simple one-click deploy option let us get the sample app up and running without the need to use our command line tool.
As a result of these changes, the sample app deployment rate jumped drastically, with almost all users preferring the sandbox cluster. Anecdotally, even experienced engineers already using CD-as-a-Service would have preferred that option had it been available when they first tried the product.
Takeaways and lessons learned
I was extremely proud of myself and the team for going from nothing to a shipped product. In hindsight, despite Armory’s fate, I believe we made the right call in trying to broaden our product offerings, as the Spinnaker product was unable to sustain the company, leading to their eventual shutdown.
For me, diving head first into product design as a full-time role at what was still a fairly young startup was a hell of an experience, to put it bluntly, but it gave me an even deeper appreciation for thinking about the user and what’s best for their needs. The lessons learned were immensely valuable.

Doing it all again
If I could do it all again, I’d have certainly done some things differently; part of growth is acknowledging your missteps and applying those lessons to the future. These are just a few:
-
I believe we could have settled on some decisions quicker, specifically around what data to present. It’s easier to ship and test rather than deliberate if you don’t have a ton of information available to you.
-
While we made a conscious decision for our onboarding UX due to various constraints, I believe we should have committed to UX affordances such as the sandbox clusters from the outset, as it may have helped our initial growth at the product’s release when marketing is at its peak.
-
Getting marketing involved earlier in development could have helped accelerate our development, as well as improve my own understanding of that process for personal growth.